The proposal machine: From RAG to context engineering
Most firms responding to an RFP have done the work before. The ones that win are faster at proving it. This issue covers RAG, MCP, and context engineering — and what civil engineering firms can build right now to stop losing proposals they should have won.

Infrastructure Catalyst
Issue #9 | March 31, 2026
Your firm's biggest competitive advantage in proposals isn't your experience. It's how fast you can prove it.
Most firms responding to an RFP have done the work before. That's not what separates winners from runners-up. The firms that win consistently are faster at proving it: right project on the table, right resume tailored, right scope framed before deadline pressure hits.
AI is changing that equation. This issue tells the story in three acts.
BEFORE 2022 to 2024: The first attempt, and why it mostly failed
When generative AI arrived, AEC firms tried the obvious thing: paste the RFP into ChatGPT and ask for a technical approach. The output was generic, missed agency-specific requirements, and required so much rewriting it wasn't worth the effort.
The experiment failed not because AI was wrong for proposals, but because generic AI has no access to your firm's actual experience. It can't write "our team managed construction phase services on a 12-mile arterial widening, coordinating utility relocations with five agencies and delivering on schedule despite two design changes" because it doesn't know that project exists. It writes the plausible-sounding version: "our team has extensive experience in roadway design and construction management."
Same words. No proof. No differentiation.
The firms that saw early results weren't using ChatGPT for drafting. They were solving a different problem first: how do you connect AI to your firm's own project library so it retrieves the right credential before it writes a single sentence?
That approach has a name. It's called RAG, Retrieval-Augmented Generation. The concept spent two years being validated in industries with identical workflows to AEC before the tools became accessible enough for firms without dedicated AI engineers.
Here's the timeline of how it developed:
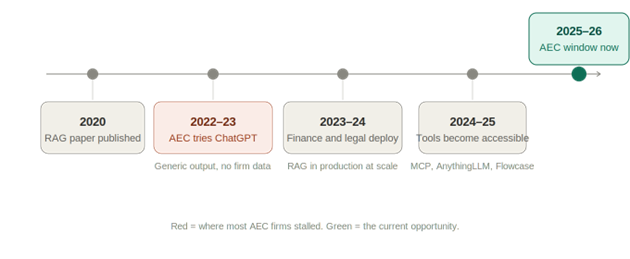
The red node marks where most AEC firms got stuck. The industries that moved past it didn't have better technology. They had more document-heavy workflows that forced the issue earlier.
NOW 2025 to 2026: Production reality, and why AEC is 18 months behind
RAG won the enterprise adoption race, and the proof is in named firms running it at scale today.
McKinsey built internal RAG systems to help consultants search institutional knowledge faster. Morgan Stanley deployed it in Wealth Management so advisors can surface and synthesize decades of internal research in seconds. WSP, one of the largest engineering firms globally, has been investing in AI-assisted knowledge management since 2023.
Legal, financial services, management consulting. Every document-heavy, proprietary-data industry that mirrors AEC workflows has been running this in production for two years.
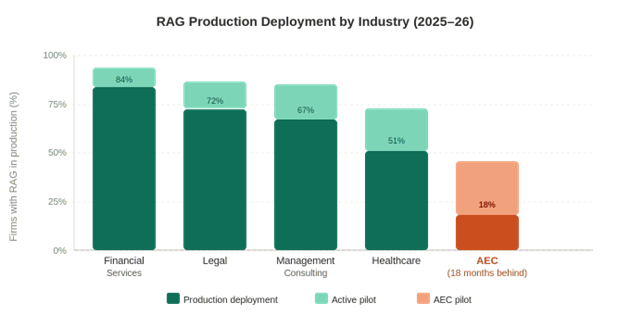
AEC is not early to this. It is late. But the gap is closable because the tools that made this accessible to large financial firms in 2023 are now accessible to a 50-person infrastructure consulting firm in 2026.
What changed is MCP, the Model Context Protocol. MCP is a standard interface between an AI model and external systems: databases, file systems, and internal APIs. Instead of every application inventing its own glue code, MCP defines a consistent way for models to discover tools, invoke them, and get structured results back. Connecting Claude to a SharePoint project library that previously required weeks of custom engineering now takes an afternoon of configuration.
Here is what a RAG-powered proposal system looks like when built on MCP:
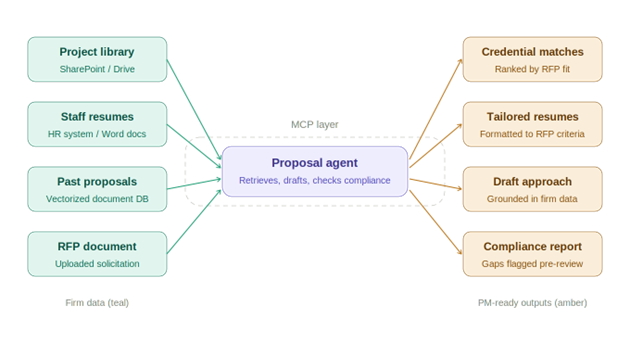
It is worth noting that this is one configuration among many. AI agents can be structured as single-purpose tools, multi-agent pipelines, memory-augmented systems, graph-based reasoners, or fully autonomous loops with human checkpoints at each stage. The landscape is genuinely wide. But for this specific application, the RAG-over-MCP pattern has emerged as the most practical starting point.
It maps directly onto infrastructure that most AEC firms already have, requires the least custom engineering to stand up, and delivers measurable value before you've built anything complex.
The teal nodes on the left are your firm's existing data sitting in SharePoint right now. The MCP layer in the center is what allows an AI agent to query those sources during a proposal rather than relying on generic training data. The amber outputs on the right are what your PM receives to review, refine, and approve before anything reaches a client.
The proposal team stops hunting credentials. They start reviewing and sharpening output. The writing that actually wins work, the technical story, the win themes, the client insight, gets more time and better thinking.
One honest limitation
40 to 60% of RAG implementations fail to reach production due to retrieval quality issues. The failure mode is almost always the data, not the AI. A proposal agent built on inconsistently named files, duplicate project descriptions, and outdated resumes produces garbage output. Confidently, at scale. Build the knowledge base first. Build the agent second.
NEXT 2026 to 2028: Context engineering, agentic memory, and the compounding advantage
RAG was the first answer to "how do we get AI to use our firm's data." Context engineering is the complete answer.
Douwe Kiela co-authored the 2020 paper that introduced RAG to the world. His take on what's happened since is direct: "I think people have rebranded it now as context engineering, which includes MCP and RAG." The shift is from one-shot retrieval to a continuous loop. The AI manages the entire information environment it operates in: documents, tools, conversation history, and memory, all cycling and updating as work progresses.
The progression from LLMs to prompt engineering to RAG to function calling to MCP servers to AI agents with large context windows is already unfolding. Each layer didn't replace the one before it. It absorbed it and made it more powerful.
For AEC proposals, the evolution looks like this:
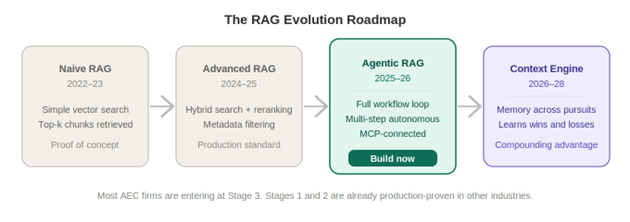
The green block is where firms can build right now. The purple block is where the compounding advantage starts to accumulate.
Here is what that compounding looks like in practice. A system with contextual memory doesn't just retrieve relevant past projects. It learns from every pursuit, maintains state across proposals, and adapts based on what worked and what didn't. It knows your fee for construction management on similar bridge rehab scopes has come in above competing firms three times. It knows your most experienced drainage engineer just rolled off a project and is available. It knows a particular county prefers a specific format for technical approach sections because you won their last two contracts and the system retained that pattern. Every RFP makes the next one faster, more accurate, and harder for competitors to match.
That is not a someday story. The infrastructure for it exists today. What's missing in most firms is the knowledge base that makes it work.
Where to start
The AI part is now the easy part. The hard part is what was always the hard part: organizing your firm's experience so it can be found.
If you have thirty minutes this week, audit your SharePoint, Dropbox, or OneDrive project library. Consistent file naming, current project descriptions, no duplicates. That is the foundation everything else builds on.
If you want to try something before your next proposal kickoff, paste the RFP scope of work into Claude and ask: "What are the top five criteria this client appears to weight most heavily, and what are the three biggest risks to a typical technical approach for this project type?" Ten minutes. A structured starting point before anyone starts writing.
One note on data safety: paste only the RFP, which is already a public document. Keep confidential project data, client names, and fee information out of any public-facing AI tool until your firm has an enterprise agreement in place. Tools like Claude for Enterprise and Microsoft Copilot operate under data agreements that prevent your inputs from being used for model training. If your firm hasn't set that up yet, treat public LLMs as a thinking tool, not a data tool.
Some firms have enterprise agreements. Some have restrictions. Some have nothing decided yet. Whatever your situation, drop it in the comments. Someone out there has already solved your exact constraint.
Joseph Dib, PE, PMP
Infrastructure Catalyst